SQL script to get table structure info without using tools
Experiment on PostgreSQL
During software development, most of the developers tend to use tools such as Navicat, HeidiSQL, etc to connect to databases for doing various activities such as writing SQL, creating views, applying indexes. One of the activities is viewing the table structure which is created during data analysis to know what information they should store in each column of the table. Here I would like to introduce about SQL script which is used to query those table's info ( DATA DICTIONARY ) from the information schema of the databases. The script we are going to introduce here is useful for creating a data dictionary especially for business analyzers or database administrators after analyzing the business flow ERD diagram.
Below is the sample format of the data dictionary which is usually used in the development stage. This table information is very vital for communication between developers and analyzers in case there is an updated change while coding. Here is the sample data dictionary of the table: tb_school
| # | Field Name | Data Type | Length | Default | KEY | IS NULL | Remark |
|---|---|---|---|---|---|---|---|
| 1 | id | int8 | 64 | nextval('tb_school_id_seq::regclass') | PK | NO | |
| 2 | code | varchar | 5 | YES | |||
| 3 | name | varchar | 100 | YES | |||
| 4 | address | varchar | 1000 | YES | |||
| 5 | description | varchar | 500 | YES | |||
| 6 | is_active | char | 1 | '1'::bpchar | YES | 1: ACTIVE 2: DEACTIVATE | |
| 7 | created_at | timestamp | 6 | YES | |||
| 8 | created_by | int8 | 64 | YES | |||
| 9 | updated_at | timestamp | 6 | YES | |||
| 10 | updated_by | int8 | 64 | YES |
We conduct our experiment based on PostgreSQL database version 12.0 and MySQL 8.0 which are the most popular nowadays. I also provide the script for each of the databases too, which you can freely use. Once again, this script is beneficial for business analysts or/and database administrators/developers.
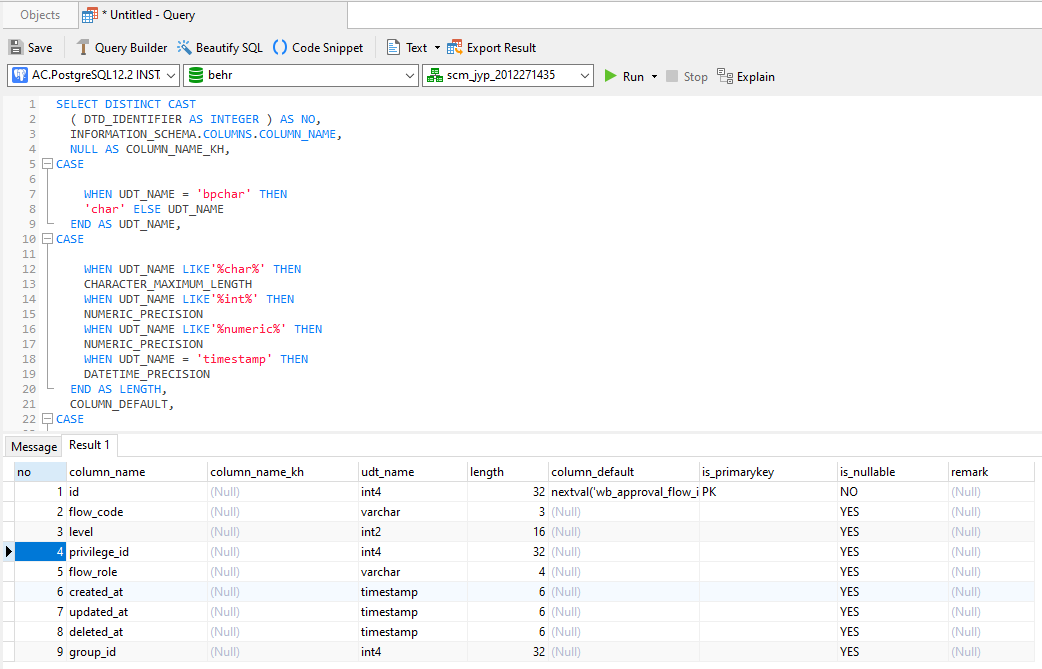
Here is the same PostgreSQL Script
SELECT DISTINCT CAST
( DTD_IDENTIFIER AS INTEGER ) AS NO,
INFORMATION_SCHEMA.COLUMNS.COLUMN_NAME,
NULL AS COLUMN_NAME_KH,
CASE
WHEN UDT_NAME = 'bpchar' THEN
'char' ELSE UDT_NAME
END AS UDT_NAME,
CASE
WHEN UDT_NAME LIKE'%char%' THEN
CHARACTER_MAXIMUM_LENGTH
WHEN UDT_NAME LIKE'%int%' THEN
NUMERIC_PRECISION
WHEN UDT_NAME LIKE'%numeric%' THEN
NUMERIC_PRECISION
WHEN UDT_NAME = 'timestamp' THEN
DATETIME_PRECISION
END AS LENGTH,
COLUMN_DEFAULT,
CASE
WHEN INFORMATION_SCHEMA.KEY_COLUMN_USAGE.COLUMN_NAME = INFORMATION_SCHEMA.COLUMNS.COLUMN_NAME THEN
'PK' ELSE''
END AS IS_PRIMARYKEY,
IS_NULLABLE,
(
SELECT
PG_CATALOG.COL_DESCRIPTION ( C.OID, INFORMATION_SCHEMA.COLUMNS.ORDINAL_POSITION :: INT )
FROM
PG_CATALOG.PG_CLASS AS C
WHERE
C.OID = ( SELECT INFORMATION_SCHEMA.COLUMNS.TABLE_NAME :: REGCLASS :: OID )
AND C.RELNAME = INFORMATION_SCHEMA.COLUMNS.TABLE_NAME
) AS REMARK
FROM
INFORMATION_SCHEMA.
COLUMNS INNER JOIN INFORMATION_SCHEMA.TABLE_CONSTRAINTS ON INFORMATION_SCHEMA.COLUMNS.TABLE_NAME = INFORMATION_SCHEMA.TABLE_CONSTRAINTS.
TABLE_NAME INNER JOIN INFORMATION_SCHEMA.KEY_COLUMN_USAGE ON INFORMATION_SCHEMA.TABLE_CONSTRAINTS.CONSTRAINT_NAME = INFORMATION_SCHEMA.KEY_COLUMN_USAGE.CONSTRAINT_NAME
WHERE
INFORMATION_SCHEMA.COLUMNS.TABLE_CATALOG = 'behr'
AND INFORMATION_SCHEMA.COLUMNS.TABLE_SCHEMA = 'scm_jyp_2012271435'
AND INFORMATION_SCHEMA.COLUMNS.TABLE_NAME = 'wb_approval_flow'
AND INFORMATION_SCHEMA.TABLE_CONSTRAINTS.CONSTRAINT_TYPE = 'PRIMARY KEY'
ORDER BY
NO ASC;
In order to use this script, you have to change the names of TABLE_CATALOG, TABLE_SCHEMA, and TABLE_NAME based on your requirement.
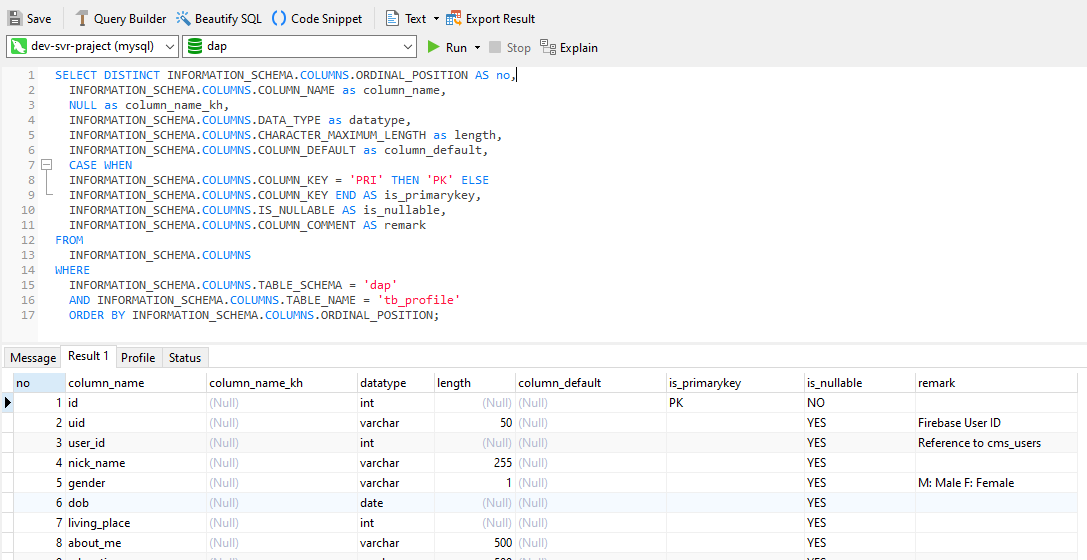
Here is the sample MySQL Script
SELECT DISTINCT INFORMATION_SCHEMA.COLUMNS.ORDINAL_POSITION AS no,
INFORMATION_SCHEMA.COLUMNS.COLUMN_NAME as column_name,
NULL as column_name_kh,
INFORMATION_SCHEMA.COLUMNS.DATA_TYPE as datatype,
INFORMATION_SCHEMA.COLUMNS.CHARACTER_MAXIMUM_LENGTH as length,
INFORMATION_SCHEMA.COLUMNS.COLUMN_DEFAULT as column_default,
CASE WHEN
INFORMATION_SCHEMA.COLUMNS.COLUMN_KEY = 'PRI' THEN 'PK' ELSE
INFORMATION_SCHEMA.COLUMNS.COLUMN_KEY END AS is_primarykey,
INFORMATION_SCHEMA.COLUMNS.IS_NULLABLE AS is_nullable,
INFORMATION_SCHEMA.COLUMNS.COLUMN_COMMENT AS remark
FROM
INFORMATION_SCHEMA.COLUMNS
WHERE
INFORMATION_SCHEMA.COLUMNS.TABLE_SCHEMA = 'dap'
AND INFORMATION_SCHEMA.COLUMNS.TABLE_NAME = 'tb_profile'
ORDER BY INFORMATION_SCHEMA.COLUMNS.ORDINAL_POSITION;
In order to use this script, you have to change the names of TABLE_SCHEMA, and TABLE_NAME based on your requirement.
Finally, I hope these snippet codes to retrieve information of tables in the database can help you to generate data dictionary of your whole system in order to communicate well within your team during software development. For further improvement of the usage, you can also create a function with my provided script so you don't have to copy/paste all over again.
About author

SETHA THAY
Software Engineer & Project Manager. I am willing to share IT knowledge, technical experiences and investment to financial freedom. Feel free to ask and contact me.
You may also like